

Find Duplicate Files Easily Across Your Drives
Out of disk space? Then it's time to tidy up and find duplicate files!
With TreeSize and SpaceObServer you can clean duplicates in regular intervals no matter if your setup is a small local system or a large server landscape. Choose the solution that fits your demand!
Clean up file copies in seconds
With TreeSize you can remove duplicate files and folders in just a few seconds - no matter where they are:
- Clear overview of all duplicates files of your system.
- Check-mark duplicates and take action immediately.
- Find folder duplicates or unique files, too.
- Network shares as well as SharePoint, Amazon S3 or Linux Server supported.
Keep all your storages clean
Clean your storage systems from file duplicates no matter where they hide.
Full control over duplicates
Delete or archive found duplicates and let other files untouched. You can even deduplicate them without data losses, just as you like!
Save a lot of time
Automatically find and report duplicates via email.
JAM Software is trusted worldwide

Find similar folders on your servers
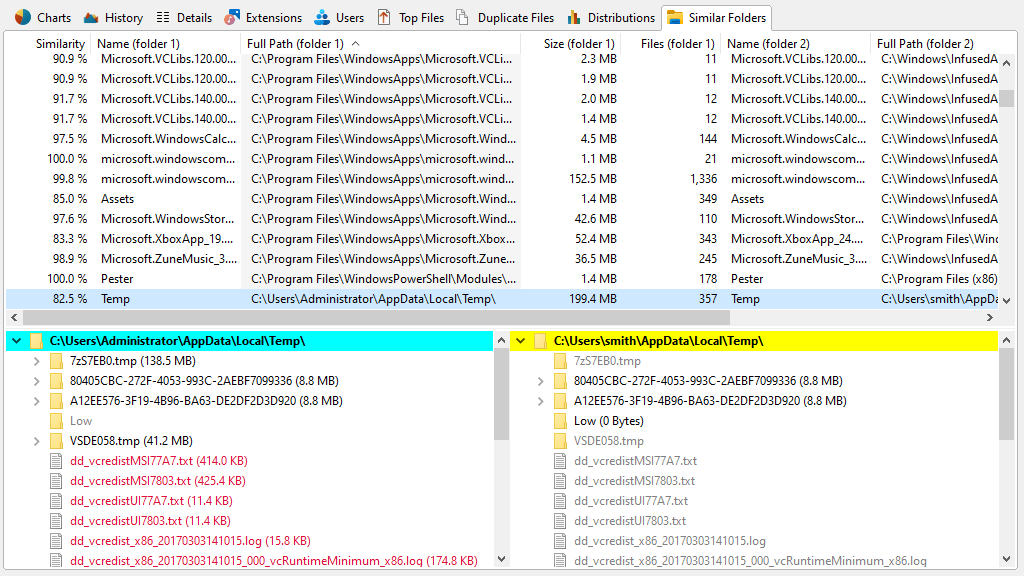
Looking for similar folders instead? TreeSize's big brother SpaceObServer will help you find similarities fast and easily.
- Check folder content and see which files differ.
- See to which percentage the compared folders match.
- Changed files are marked in red.