

SpaceObServer v8.6: How We Fundamentally Optimized Database Performance
Why This Release Is Different
Some releases introduce a major new feature. SpaceObServer v8.6 takes a different approach: we focused on the foundation. A new embedded database, optimized queries, faster permission scans. What might sound like dry infrastructure work at first glance has a significant impact in practice. Data volumes are growing rapidly, the unstructured data cost keeps rising, and so do the demands on database performance.
In this article, we show which problems we solved, why we made certain decisions, and how AI helped us along the way.
PostgreSQL as the New Embedded Database
The Problem with Firebird
SpaceObServer stores all scan results in a SQL database. For larger environments, we have always recommended a dedicated Microsoft SQL Server. But not every customer wants to set up a SQL Server just for an initial evaluation or a smaller installation. That is exactly what the embedded database was designed for: a database that installs alongside SpaceObServer and works immediately without any additional configuration.
Until now, this embedded solution was based on Firebird Embedded, an open-source database. The advantage: one click in the installer, and the database was up and running. The disadvantage became increasingly noticeable as data volumes grew. Firebird Embedded hit its limits with larger scan results, and queries became slow. Performance fell significantly behind what customers were used to from a SQL Server.
Our customer surveys show that roughly 30% of all SpaceObServer installations use the embedded database. This is not an edge case but a central usage path that we had to take seriously.
The Solution: PostgreSQL Out-of-the-Box
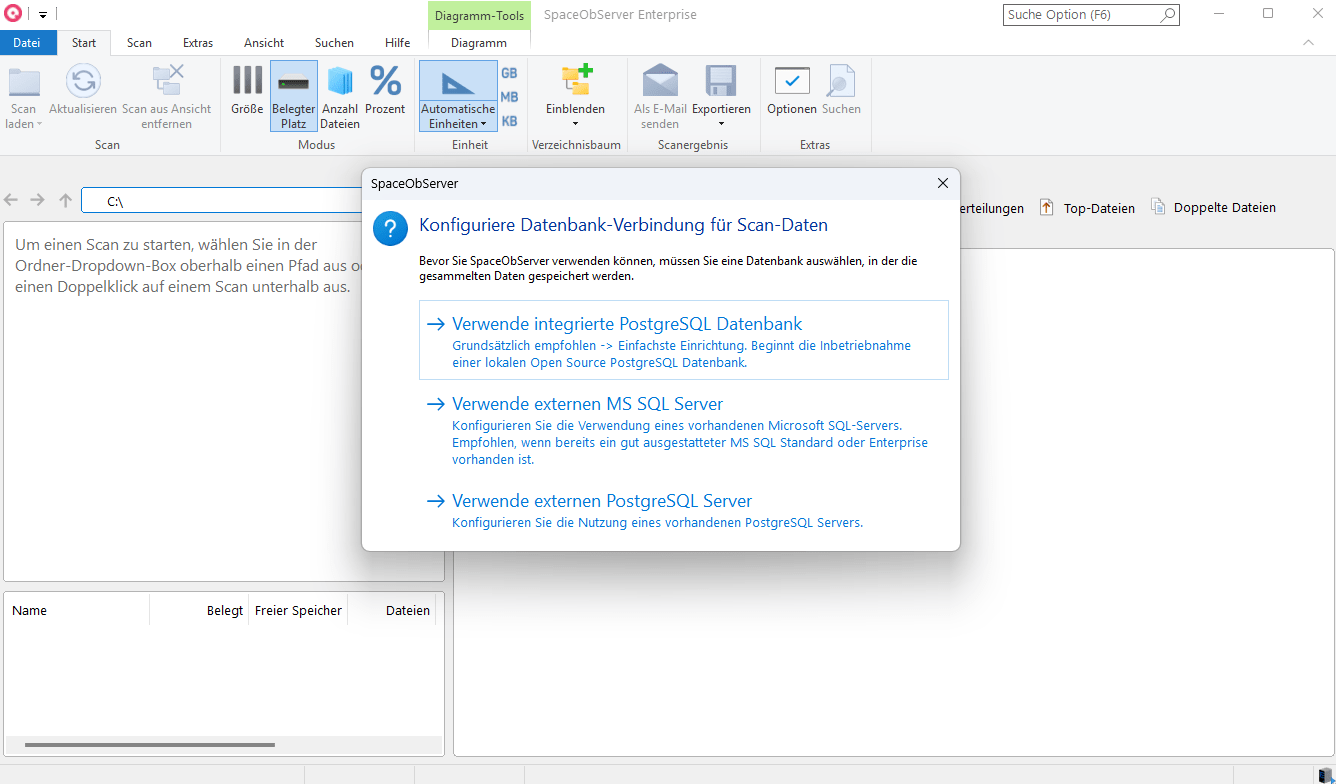
After a thorough evaluation, we chose PostgreSQL as the new bundled zero-configuration database. PostgreSQL is a mature, full-featured SQL server with excellent performance and an outstanding reputation in the database world.
The key point: we were able to integrate PostgreSQL into our installer in a way that preserves the one-click setup experience. You install SpaceObServer, select PostgreSQL on “localhost,” and SpaceObServer sets up a fully functional PostgreSQL server in the background that is ready to use immediately. No manual setup, no configuration files, no separate download.
Performance is at least on par with Microsoft SQL Server Express. For a database that runs with a single click and zero pre-configuration, that is exceptional in this software category.
Fewer Databases, Higher Quality
With the switch to PostgreSQL, we also consolidated the list of officially supported databases. Starting with v8.6, SpaceObServer officially supports two database systems:
- Microsoft SQL Server (for large enterprise environments)
- PostgreSQL (as an embedded solution and for standalone installations)
Existing installations running Firebird Server, MySQL, or MariaDB will of course continue to work. However, new databases can no longer be created with these systems, and support will be phased out in a future version. The reason: every supported database means its own query dialects, its own optimizations, and its own test scenarios. By focusing on two proven systems, we can ensure quality and performance much more effectively and efficiently.
AI-Powered Performance Optimizations
In addition to the database switch, we systematically optimized numerous existing database queries in v8.6. For the first time, we used AI-powered code analysis in this process.
Specifically, we collected known slow database operations and systematically examined them for optimization potential using AI tools. The AI did not just analyze individual queries in isolation. It also considered how they interacted with indexes, execution plans, and the specific characteristics of each database engine.
In some cases, the AI suggested restructurings that we would not have come up with during manual review, such as dissolving nested subqueries or strategically rewriting joins. In parallel, we built dedicated test systems with large datasets to measure every proposed change under realistic conditions.
A Concrete Example: Wildcard Filters on Paths
One of the most common operations in SpaceObServer is filtering file paths with wildcards, for example “show me all files whose path contains the term Backup.” This query was extremely slow in certain scenarios.
The cause: for case-insensitive comparison, every path in the database was first converted to uppercase and then compared. With millions of records, that meant millions of string transformations on every single query. The database could not use its internal indexes because the values were modified at runtime.
In hindsight, the solution was obvious: instead of manually transforming the data, we now use the native case-insensitive function of the respective database. SQL Server and PostgreSQL both provide their own highly optimized mechanisms for this (collations and ILIKE, respectively). The result: up to 10x faster wildcard filters on paths.
We found and fixed this pattern in multiple places: a suboptimal implementation that goes unnoticed with small datasets but becomes a problem with millions of files.
Faster Permission Scans
The NTFS permission analysis is one of SpaceObServer’s unique selling points, especially in the context of compliance requirements. Anyone who needs to demonstrate who has access to which data can hardly avoid automated permission analysis.
Windows permissions are complex, though. Behind every single file lies a multi-layered structure of Access Control Lists (ACLs) with inheritance rules, group permissions, and fine-grained access rights. In practice, the permission metadata of a file can be ten times the size of the actual file metadata (name, size, date).
When storing this permission data in the database, SpaceObServer relies on deduplication: identical permission structures are stored only once and then referenced. In v8.6, we discovered that this deduplication was not optimally implemented. The system was redundantly querying too many permission entries, which negatively affected both the database storage requirements and the scan speed. Additionally, we added in-memory caching during scans, allowing us to determine more quickly whether an ACL already exists in the database.
After the optimization, scans with permission collection enabled are significantly faster, and the database grows less with the same amount of data. For customers who use SpaceObServer for compliance reporting, this is a noticeable improvement in their daily workflow. Especially in environments where the unstructured data cost rises due to uncontrolled growth, faster permission scans help maintain oversight. Whether it is regular reviews of permission structures or preparation for an audit: the optimized deduplication in storage accelerates exactly these scenarios.
Conclusion
SpaceObServer v8.6 is not a release with a single headline feature but one that strengthens the foundation for everything that follows. With PostgreSQL as the new zero-configuration database, 30% of our customers get significantly better performance without having to change their workflow. The AI-powered query optimizations speed up everyday operations by a factor of 10. And the optimized permission scans make compliance analysis faster and more efficient.
If you are already using SpaceObServer, the update is well worth it. If you have not tried SpaceObServer yet: the new embedded database makes getting started easier than ever before. Try SpaceObServer for free now.